제1장 : R 기초와 데이터 마트
먼저 데이터 분석을 수행할 환경의 경로를 설정합니다.
setwd('C:/Users/wooil/Documents/GitHub/ADP')
getwd()
‘C:/Users/wooil/Documents/GitHub/ADP’
제1절 R 기초
R의 데이터 구조
1) 벡터
x = c(1, 10, 24, 40) # 숫자형 벡터
y = c("사과", "바나나", "오렌지") # 문자형 벡터
z = c(TRUE, FALSE, TRUE) # 논리 연산자 벡터
x <- c(1, 10, 24, 40) # 숫자형 벡터
y <- c("사과", "바나나", "오렌지") # 문자형 벡터
z <- c(TRUE, FALSE, TRUE) # 논리 연산자 벡터
# (참고) '=', '<-' : 우측 값을 좌측 변수에 할당
print(x)
print(y)
print(z)
[1] 1 10 24 40
[1] "사과" "바나나" "오렌지"
[1] TRUE FALSE TRUE
xy = c(x,y) # 벡터와 벡터 결합하여 새로운 벡터 생성
print(xy)
[1] "1" "10" "24" "40" "사과" "바나나" "오렌지"
2) 행렬
mx = matrix(c(1,2,3,4,5,6), ncol=2) # 컬럼이 3개인 행렬(디폴트 열기준)
mx2 = matrix(c(1,2,3,4,5,6), ncol=2, byrow=TRUE) # 컬럼이 3개인 행렬(행기준)
print(mx)
print(mx2)
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
[,1] [,2]
[1,] 1 2
[2,] 3 4
[3,] 5 6
rbind : 행 추가, cbind : 열 추가
r1 = c(10, 10)
c1 = c(20, 20, 20)
print(rbind(mx, r1))
print(cbind(mx2, c1))
[,1] [,2]
1 4
2 5
3 6
r1 10 10
c1
[1,] 1 2 20
[2,] 3 4 20
[3,] 5 6 20
3) 데이터프레임
income = c(100, 200, 150, 300, 900)
car = c("kia", "hyundai", "kia", "toyota", "lexus")
marriage = c(FALSE, FALSE, FALSE, TRUE, TRUE)
df = data.frame(income, car, marriage)
print(df)
income car marriage
1 100 kia FALSE
2 200 hyundai FALSE
3 150 kia FALSE
4 300 toyota TRUE
5 900 lexus TRUE
외부 데이터 불러오기
1) CSV파일 불러오기
dataset.csv : 엑셀 등으로 임의로 만든 데이터 파일
data1 <- read.table("dataset.csv", header = TRUE, sep = ",")
data2 <- read.csv("dataset.csv", header = TRUE)
print(data1)
no income
1 1 50000000
2 2 45000000
3 3 40000000
4 4 35000000
5 5 30000000
6 6 25000000
7 7 20000000
8 8 15000000
9 9 10000000
10 10 5000000
print(data2)
no income
1 1 50000000
2 2 45000000
3 3 40000000
4 4 35000000
5 5 30000000
6 6 25000000
7 7 20000000
8 8 15000000
9 9 10000000
10 10 5000000
R의 기초 함수
1) 수열 생성하기
# 1을 3회 반복
print(rep(1, 3))
# 1에서 3까지 연속된 수
print(seq(1, 3))
# 1에서 3까지 연속된 수
print(1:3)
# 1에서 11까지 공차가 2인 등차수열
print(seq(1, 11, by=2))
# 1에서 11까지 항이 6개인 등차수열
print(seq(1, 11, length=6))
# 1에서 11까지 항이 8개인 등차수열
print(seq(1, 11, length=8))
# 2에서 5까지 연속된 수를 각 3회 반복
print(rep(2:5, 3))
[1] 1 1 1
[1] 1 2 3
[1] 1 2 3
[1] 1 3 5 7 9 11
[1] 1 3 5 7 9 11
[1] 1.000000 2.428571 3.857143 5.285714 6.714286 8.142857 9.571429
[8] 11.000000
[1] 2 3 4 5 2 3 4 5 2 3 4 5
2) 기초적인 수치 계산
a = 1:10
print(a)
print(a + a)
print(a - a)
print(a * a)
print(a / a)
[1] 1 2 3 4 5 6 7 8 9 10
[1] 2 4 6 8 10 12 14 16 18 20
[1] 0 0 0 0 0 0 0 0 0 0
[1] 1 4 9 16 25 36 49 64 81 100
[1] 1 1 1 1 1 1 1 1 1 1
a = c(2,7,3) # 열벡터
b = t(a) # 행벡터
print(a)
print(b)
[1] 2 7 3
[,1] [,2] [,3]
[1,] 2 7 3
a * b # 스칼라 곱
a %*% b # 행렬 곱
| 4 | 49 | 9 |
| 4 | 14 | 6 |
| 14 | 49 | 21 |
| 6 | 21 | 9 |
mx = matrix(c(1,2,3,4), ncol=2)
mx_inv = solve(mx) # mx의 역행렬
mx
mx_inv
| 1 | 3 |
| 2 | 4 |
| -2 | 1.5 |
| 1 | -0.5 |
mx %*% mx_inv # 결과 : 단위행렬
| 1 | 0 |
| 0 | 1 |
a = 1:10
# a의 평균
mean(a)
# a의 분산
var(a)
# a의 표준편차
sd(a)
# a의 합
sum(a)
# a의 중앙값
median(a)
# a의 로그값
print(log(a))
# a와 a의 공분산
cov(a, a)
# a와 log(a)의 공분산
cov(a, log(a))
# a와 a의 상관계수
cor(a, a)
# a와 log(a)의 상관계수
cor(a, log(a))
5.5
9.16666666666667
3.02765035409749
55
5.5
[1] 0.0000000 0.6931472 1.0986123 1.3862944 1.6094379 1.7917595 1.9459101
[8] 2.0794415 2.1972246 2.3025851
9.16666666666667
2.11206237777995
1
0.951662390427133
# a의 요약 통계량 (최솟값/1사분위수/중앙값/평균값/3사분위수/최댓값)
summary(a)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 3.25 5.50 5.50 7.75 10.00
R 데이터 핸들링
1) 벡터형 변수
b = c("a", "b", "c", "d", "e")
print(b[1])
print(b[-2])
print(b[c(-2,-3)])
print(b[c(2,3)])
[1] "a"
[1] "a" "c" "d" "e"
[1] "a" "d" "e"
[1] "b" "c"
2) 행렬/데이터 프레임 형태의 변수
income = c(100, 200, 150, 300, 900)
car = c("kia", "hyundai", "kia", "toyota", "lexus")
marriage = c(FALSE, FALSE, FALSE, TRUE, TRUE)
df = data.frame(income, car, marriage)
print(df)
income car marriage
1 100 kia FALSE
2 200 hyundai FALSE
3 150 kia FALSE
4 300 toyota TRUE
5 900 lexus TRUE
print(df[2,2])
print(df[-1])
print(df[-2])
print(df[-1,-1])
print(df[2,])
print(df[,2])
[1] hyundai
Levels: hyundai kia lexus toyota
car marriage
1 kia FALSE
2 hyundai FALSE
3 kia FALSE
4 toyota TRUE
5 lexus TRUE
income marriage
1 100 FALSE
2 200 FALSE
3 150 FALSE
4 300 TRUE
5 900 TRUE
car marriage
2 hyundai FALSE
3 kia FALSE
4 toyota TRUE
5 lexus TRUE
income car marriage
2 200 hyundai FALSE
[1] kia hyundai kia toyota lexus
Levels: hyundai kia lexus toyota
반복 구문과 조건문
1) for 반복 구문
a = c()
for (i in 1:9){
a[i] = i * i
}
print(a)
[1] 1 4 9 16 25 36 49 64 81
isum = 0
for (i in 1:100){
isum = isum + i
}
cat("1부터 100까지의 합 =", isum, "입니다.", "\n")
1부터 100까지의 합 = 5050 입니다.
2) while 반복 구문
x=0
while (x<5){
x=x+1
print(x)
}
[1] 1
[1] 2
[1] 3
[1] 4
[1] 5
3) if~else 조건문
StatScore = c(88, 90, 87, 92, 75, 65, 93, 54, 85, 90)
over90 = rep(0, length(StatScore))
for (i in 1:length(StatScore)){
if (StatScore[i] >= 90) over90[i] = 1
else over90[i] = 0
}
print(over90)
cat("90점을 넘은 사람의 수는 ", sum(over90), "명 입니다.", sep="")
[1] 0 1 0 1 0 0 1 0 0 1
90점을 넘은 사람의 수는 4명 입니다.
사용자 정의 함수
addto = function (a) {
isum=0
for (i in 1:a){
isum = isum + i
}
print(isum)
}
print(addto(10))
print(addto(100))
[1] 55
[1] 55
[1] 5050
[1] 5050
기타 유용한 기능들
1) paste
number = 1:10
alphabet = c("a", "b", "c")
print(paste(number, alphabet))
print(paste(number, alphabet, sep=" to the "))
[1] "1 a" "2 b" "3 c" "4 a" "5 b" "6 c" "7 a" "8 b" "9 c" "10 a"
[1] "1 to the a" "2 to the b" "3 to the c" "4 to the a" "5 to the b"
[6] "6 to the c" "7 to the a" "8 to the b" "9 to the c" "10 to the a"
2) substr
substr("BigDataAnalysis", 1, 4)
country = c("Korea", "Japan", "China", "Singapore", "Russia")
print(substr(country, 1, 3))
‘BigD’
[1] "Kor" "Jap" "Chi" "Sin" "Rus"
3) 자료형 데이터 구조 변환
x = matrix(c(1,2,3,4,5,6), ncol=2)
print(as.data.frame(x)) # 데이터프레임
print(as.list(x)) # 리스트
print(as.matrix(x)) # 행렬
print(as.vector(x)) # 벡터
print(as.factor(x)) # 팩터
V1 V2
1 1 4
2 2 5
3 3 6
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
[[4]]
[1] 4
[[5]]
[1] 5
[[6]]
[1] 6
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
[1] 1 2 3 4 5 6
[1] 1 2 3 4 5 6
Levels: 1 2 3 4 5 6
as.integer(3.14)
as.numeric('foo')
as.character(101)
as.numeric(FALSE)
as.logical(0.35)
as.logical(0)
3
Warning message in eval(expr, envir, enclos):
"강제형변환에 의해 생성된 NA 입니다"
<NA>
‘101’
0
TRUE
FALSE
income = c(100, 200, 150, 300, 900)
car = c("kia", "hyundai", "kia", "toyota", "lexus")
marriage = c(FALSE, FALSE, FALSE, TRUE, TRUE)
df = data.frame(income, car, marriage)
print(df) # income 숫자형 벡터, car 문자형 벡터, marriage 논리형 벡터
print(as.matrix(df)) # matrix 변환 후 모든 컬럼 문자형 벡터화
income car marriage
1 100 kia FALSE
2 200 hyundai FALSE
3 150 kia FALSE
4 300 toyota TRUE
5 900 lexus TRUE
income car marriage
[1,] "100" "kia" "FALSE"
[2,] "200" "hyundai" "FALSE"
[3,] "150" "kia" "FALSE"
[4,] "300" "toyota" "TRUE"
[5,] "900" "lexus" "TRUE"
4) 문자열을 날짜로 변환
print(Sys.Date()) # 오늘 날짜
a = '2019-07-08'
b = '07/08/2019'
print(as.Date(a))
print(as.Date(b, format = "%m/%d/%Y"))
[1] "2019-09-28"
[1] "2019-07-08"
[1] "2019-07-08"
5) 날짜를 문자열로 변환
format(Sys.Date())
as.character(Sys.Date())
format(Sys.Date(), format="%m/%d/%Y")
‘2019-09-28’
‘2019-09-28’
‘09/28/2019’
format 함수로 날자 정보 추출
format(Sys.Date(), '%a') # 요일
format(Sys.Date(), '%b') # 월
format(Sys.Date(), '%m') # 두자리 숫자로 월
format(Sys.Date(), '%d') # 두자리 숫자로 일
format(Sys.Date(), '%y') # 두자리 숫자로 연도
format(Sys.Date(), '%Y') # 네자리 숫자로 연도
‘토’
‘9’
‘09’
‘28’
‘19’
‘2019’
R 그래픽 기능
df = iris # iris 샘플 데이터 (Sepal:꽃받침, Petal:꽃잎)
1) 산점도 그래프(Scatter Plot)
plot(df$Sepal.Length, df$Sepal.Width) # 꽃받침 길이와 꽃받침 너비 산점도
plot(df$Sepal.Length, df$Petal.Length) # 꽃받침 길이와 꽃잎 길이 산점도
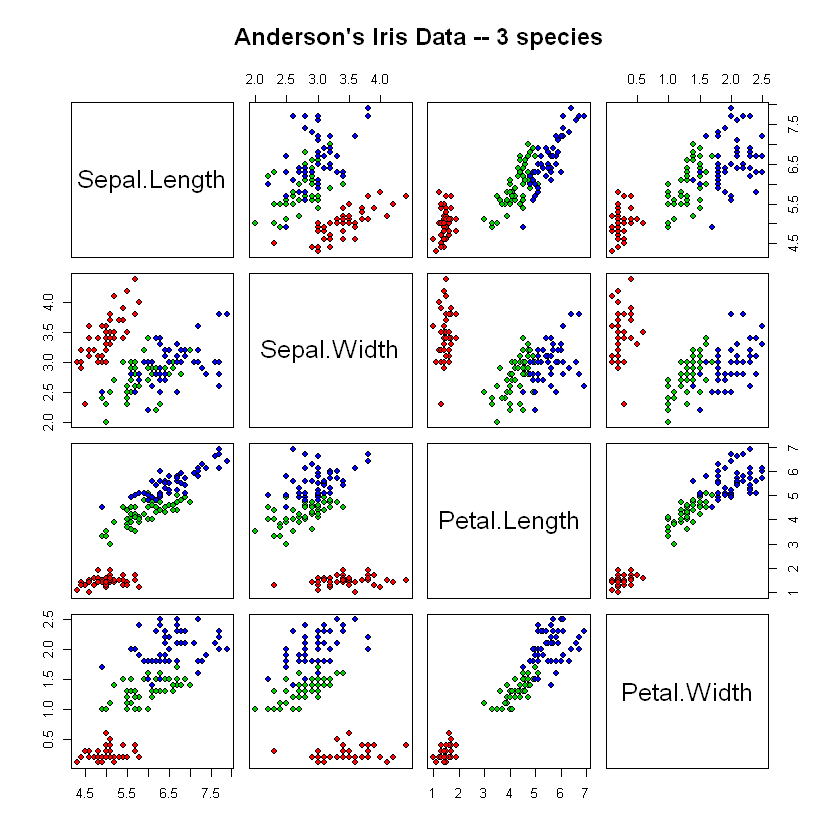
2) 산점도 행렬(Scatter Plot Matrix)
pairs(df[1:4],
main = "Anderson's Iris Data -- 3 species",
pch = 21,
bg = c("red", "green3", "blue")[unclass(df$Species)])
3) 히스토그램과 상자그림(Histogram and Box-Plot)
StatScore = c(88, 90, 87, 92, 75, 65, 93, 54, 85, 90)
hist(StatScore, prob=T)
boxplot(StatScore)
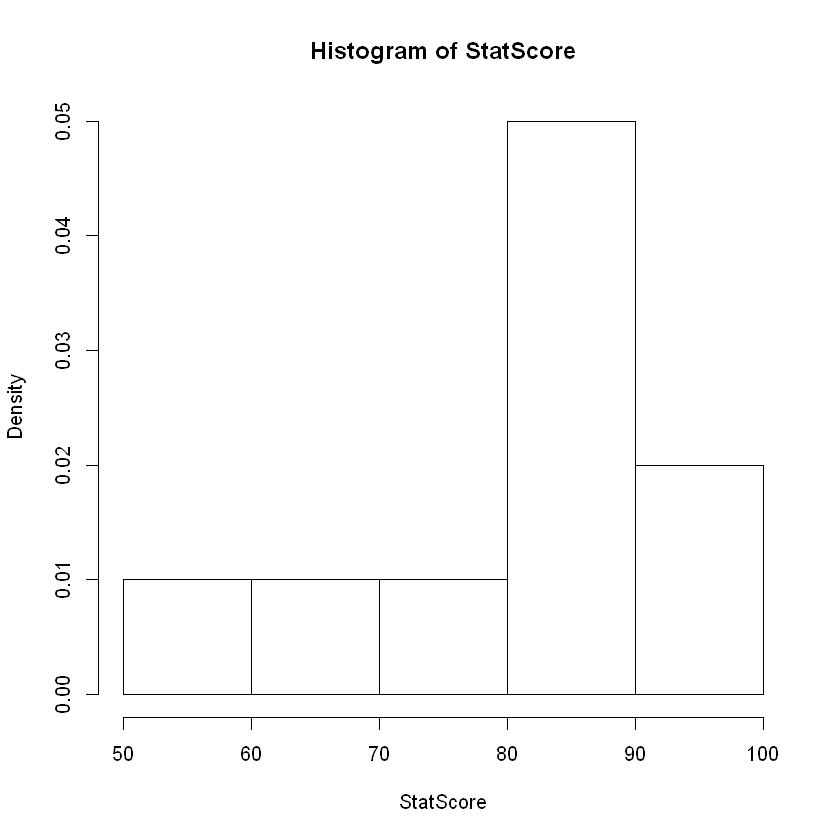
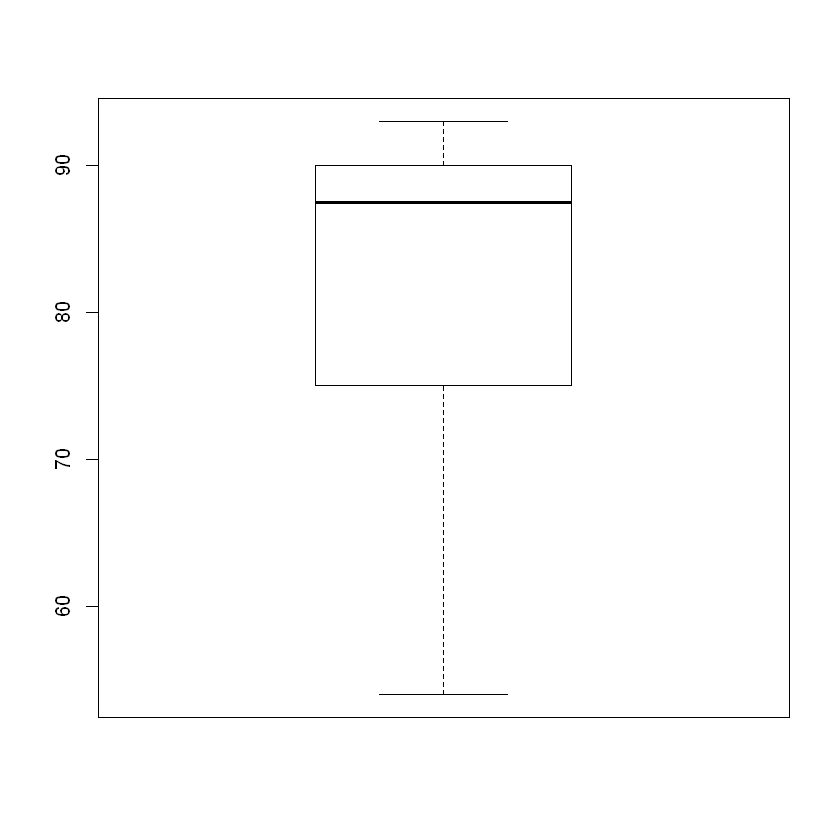
댓글남기기